Search That Actually Understands Your Meetings
Every meeting app has search. Type a word, get a list of meetings containing that word. Some apps go further with semantic search — understanding that “budget” and “financial plan” mean similar things.
But try asking: “What has Sarah said about the budget recently?”
That question carries four different kinds of evidence:
- Keywords — “budget” should match literally
- Meaning — related concepts like “costs” or “spending” should match too
- Identity — “Sarah” is a known person who appeared in specific meetings
- Time — “recently” means the last few weeks, not six months ago
Most meeting apps handle #1. Some handle #2. Almost none handle #3 or #4. And none of them combine all four in a principled way.
We wanted to fix this in Oatmeal. Along the way, we found a piece of mathematics that made the solution surprisingly clean.
The Problem With How Search Works Today
Search engines rank documents using BM25 — a formula from the 1970s that scores how well a document’s words match your query. It works well, but it produces unbounded scores that mean nothing in absolute terms. A score of 12.7 tells you nothing unless you compare it to other scores from the same query.
Modern apps add vector search — embedding queries and documents into a shared mathematical space where semantic similarity can be measured. This catches conceptual matches that keyword search misses.
But then you need to combine the two signals. The industry standard is Reciprocal Rank Fusion (RRF): take the rank position from each method, convert to a score using 1/(60 + rank), and add them up. That magic number 60? It comes from a 2009 paper. It works okay. Nobody knows why it’s 60 and not 50 or 70.
The deeper problem: RRF throws away score magnitudes entirely. If keyword search gives a document 15.2 and the next document 14.8, those are a near-tie. But 15.2 and 2.1 is a clear winner. RRF treats both cases the same — rank 1 and rank 2.
Now try adding a third signal — entity awareness, knowing which people and projects appear in which meetings. You need to tune three weights. Add temporal recency as a fourth and you have four interacting hyperparameters. Every new kind of intelligence makes the system harder to tune.
This is where we were: a hybrid search that worked but couldn’t gracefully incorporate the rich structured data we’d already built — entity graphs, relationship maps, temporal metadata.
The Elegant Solution: Let Bayes Handle It
In January 2026, Jaepil Jeong published a paper called “Bayesian BM25” that reframed the problem entirely. The core insight: BM25 was born from probability theory in the 1970s, but somewhere along the way it stopped being probabilistic. Its output is a relevance score, not a probability. What if we simply completed the math?
Starting from Bayes’ theorem — “what is the probability this document is relevant, given this BM25 score?” — the posterior simplifies to:
P(relevant | score) = sigmoid(alpha * (score - beta))The sigmoid function emerges algebraically. It’s not a design choice borrowed from neural networks — it’s the mathematically inevitable answer to the question “what does this score mean as a probability?”
Now a BM25 score becomes a calibrated number between 0 and 1. Something you can reason about: 0.85 means “very likely relevant.” 0.15 means “probably not.”
The same treatment applies everywhere. Cosine similarity becomes a probability. Entity matching — “Sarah appeared in this meeting 3 times” — becomes a probability. Temporal recency — “this meeting was 5 days ago” — becomes a probability.
Every signal speaks the same language.
When Signals Agree, Confidence Should Rise
Here’s where it gets interesting. You have four probabilities, one from each signal. How do you combine them?
The naive approach — multiply them — has a fatal flaw. If four signals each say P=0.7, the product is 0.7 x 0.7 x 0.7 x 0.7 = 0.24. Four signals agreeing that something is relevant somehow produce a result that says it’s probably not relevant. Adding more evidence makes things worse. This is the conjunction shrinkage problem.
Jeong’s companion paper solves this with what he calls the log-odds conjunction — a three-stage pipeline:
Stage 1: Take the geometric mean of all probabilities — capturing average confidence regardless of how many signals contribute.
Stage 2: Move to log-odds space and add an agreement bonus: alpha * log(n), where n is the number of concurring signals. With alpha=0.5, four agreeing signals double the odds.
Stage 3: Convert back to probability via sigmoid.
The difference is striking:
| Signals agreeing at P=0.7 | Product | Log-odds conjunction |
|---|---|---|
| 2 signals | 0.49 | 0.77 |
| 3 signals | 0.34 | 0.80 |
| 4 signals | 0.24 | 0.83 |

Four agreeing signals produce 0.83, not 0.24. Confidence rises with agreement — which is how evidence actually works.
And here’s what makes it practical: adding a new signal requires zero changes to the fusion logic. Each signal needs its own calibration — a sigmoid midpoint for BM25 scores, a mapping for cosine similarity, a decay curve for recency. But once calibrated to [0, 1], any signal plugs into the same conjunction. No cross-signal weight tuning. No combinatorial hyperparameter search. The fusion scales by itself.
What This Means for Meeting Search
Oatmeal already tracks rich structured information about your meetings:
- Entities — people, projects, and companies mentioned, linked across meetings
- Relationships — who manages whom, who works on which project
- Temporal data — when meetings happened, when entities were last discussed
- Transcripts — full text with word-level timestamps
Until now, search only used keywords and semantics. All that structured intelligence sat in the database, unused during retrieval.
With Bayesian fusion, each becomes a first-class evidence channel:
"What has Sarah said about the budget recently?"
Keyword search: "budget" matches in 12 meetings → P_keyword
Semantic search: query embedding similar to 8 meetings → P_semantic
Entity awareness: Sarah mentioned in 23 meetings → P_entity
Temporal recency: "recently" = last 30 days, 4 meetings → P_temporal
Log-odds conjunction: meetings where ALL signals agree
→ The 3 meetings from the last month where Sarah discussed budget
score highest, with calibrated confidence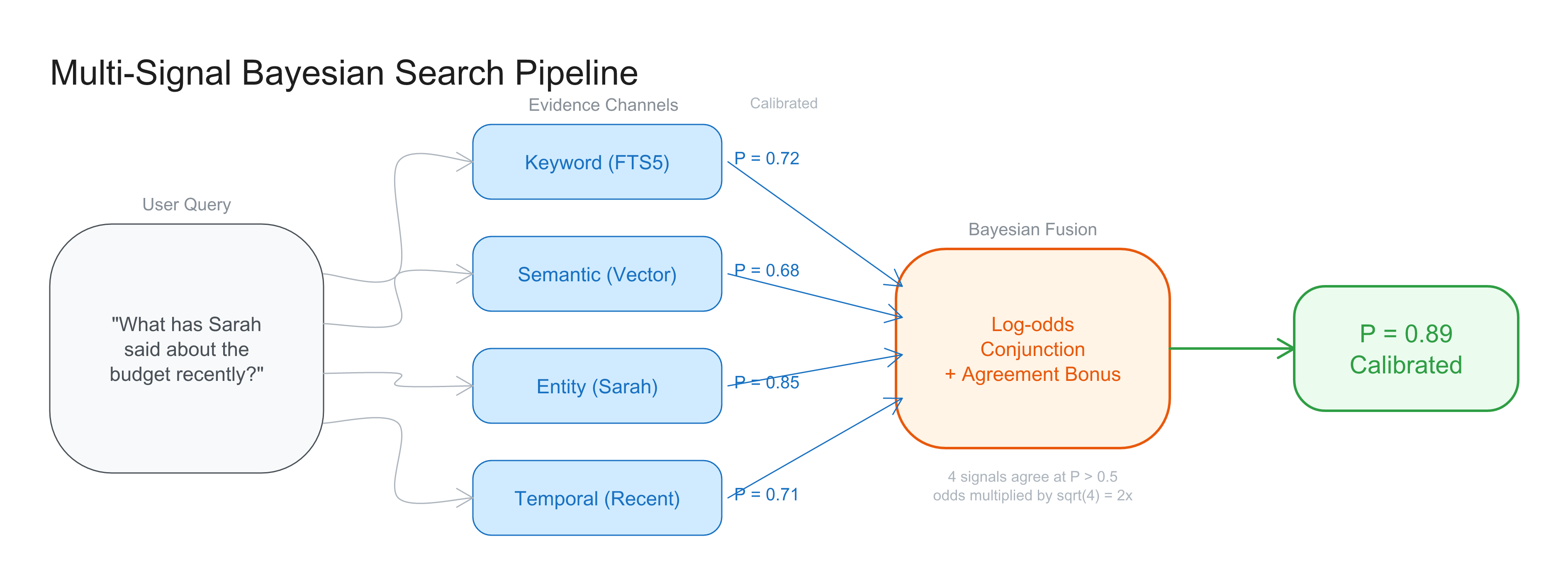
Crucially, entity and temporal signals aren’t filters — they don’t throw away everything outside a hard boundary. They’re evidence. A meeting from 31 days ago still contributes, just with slightly lower temporal probability. A meeting where “S. Chen” (an alias for Sarah) appears still gets entity probability through alias resolution. Nothing is discarded. Everything is weighed.
Calibrated Confidence Changes RAG Quality
There’s a downstream benefit we didn’t anticipate. When you ask Oatmeal a question across all your meetings, we retrieve relevant chunks and feed them to a local language model (Qwen3-4B running on your Mac) to synthesize an answer.
Previously, we sent the top 5 chunks regardless of actual relevance. Ask about something never discussed in your meetings and the model gets 5 irrelevant chunks — then hallucinates confidently about things that were never said.
A note on what “calibrated” means here: the conjunction output is a confidence score bounded to [0, 1] that preserves ordering — higher means more relevant. It’s not a literal probability of intersection in the statistical sense. But for ranking and threshold decisions, that’s exactly what you need.
With these calibrated scores, we can set a confidence threshold. If no chunk scores above 0.2, nothing gets sent to the model. Instead: “I don’t have information about this in your meetings.” Less noise in, fewer hallucinations out.
This matters especially for small local models. Research consistently shows that retrieval quality matters more than model size — a well-tuned pipeline feeding a 4B parameter model outperforms a sloppy pipeline feeding a 70B model.
The Implementation Is Tiny
The fusion layer itself is about 30 lines of Swift. Each signal also needs a calibrator — a sigmoid transform for BM25, a linear map for cosine similarity, an exponential decay for recency — but these are small, independent functions. No dependencies. No models to download. No cloud APIs. Pure math:
sigmoid(x) → calibrate raw score to probability
logit(p) → move to log-odds space
geometric mean + agreement bonus → fuse multiple signals
sigmoid → back to probabilityIt slots between our existing search engines — which don’t change — and our result ranking, which gets better. FTS5 still handles keywords. vDSP-accelerated vector search still handles semantics. We add entity and temporal queries on existing SQLite tables. Each produces a score. Bayesian fusion combines them.
The magic number 60 in RRF is gone. In its place: Bayes’ theorem, which has been the right answer since 1763.
The Research: Closing a Fifty-Year Gap
The research behind this deserves attention. It’s not an incremental improvement — it’s the completion of a mathematical framework that’s been open since 1976.
The Gap Robertson Left Open
In 1976, Stephen Robertson published the Probability Ranking Principle — the theoretical foundation for ranking documents by probability of relevance. BM25, the ranking function that grew out of this work, became the backbone of search. Google used it. Elasticsearch uses it. SQLite’s FTS5 uses it.
But Robertson’s framework had an unfinished edge. BM25 begins in probability theory — its derivation starts from “what is the probability this document is relevant?” — but its output is an unbounded score. Somewhere between the theory and the implementation, the probability got lost. A BM25 score of 8.3 isn’t a probability. It’s just a number bigger than 7.1.
For fifty years, the information retrieval community worked around this gap. Scores were normalized ad hoc, combined with arbitrary weights, or reduced to rank positions. It worked well enough.
Jaepil Jeong and Bayesian BM25
Jaepil Jeong is the founder of Cognica, where he builds database engines that integrate document storage, full-text search, dense vector similarity, and ML pipelines into a single system. He started programming in assembly on Intel 8088 processors at age ten and has spent nearly three decades at the intersection of database systems, information retrieval, and programming language theory.
In January 2026, he published “Bayesian BM25 — A Probabilistic Framework for Hybrid Text and Vector Search”, which closes Robertson’s gap by completing the Bayesian derivation. The key finding: follow Bayes’ theorem to its conclusion — ask “what is the posterior probability of relevance given this BM25 score?” — and the sigmoid function emerges algebraically. It isn’t borrowed from neural networks. It isn’t a design choice. It’s the mathematical answer to the question BM25 was always trying to ask.
The paper proves formal guarantees: monotonicity (higher scores always produce higher probabilities), bounded priors (no degenerate edge cases), and numerical stability across the full score range. It includes 10 validation experiments, all verified. The framework has been running in production in Cognica’s C++ database engine since February 2025.
The Conjunction Paper: Why Neurons Are Inevitable
A month later, Jeong published a companion paper — “From Bayesian Inference to Neural Computation” — extending the framework to combining multiple evidence signals.
This paper tackles the conjunction shrinkage problem head-on: when you multiply probabilities, agreeing evidence paradoxically reduces confidence. The solution is a three-stage pipeline operating in log-odds space, with an agreement bonus that correctly amplifies confidence when independent signals concur.
The remarkable finding is structural. The complete pipeline — sigmoid calibration of inputs, linear combination in log-odds space, additive bias, sigmoid output — turns out to be formally equivalent to a single artificial neuron:
y = sigmoid(sum(w_i * x_i) + b)As Jeong writes in his accompanying essay:
“The neuron is not an invention of neuroscience or machine learning. It is a theorem of probability.”
Three independent intellectual traditions — probability theory (Bayes, 1763), information retrieval (Robertson, 1976), and neural computation (McCulloch & Pitts, 1943) — arrive at the same mathematical structure through completely different paths.
Practical Implications Beyond Search
The bounded [0, 1] output and monotonic sigmoid also unlock a classical optimization: WAND/BMW pruning. Because you know the maximum possible score any document can achieve, you can skip documents that can’t possibly rank high enough — with zero accuracy loss. Empirical skip rates range from 50% to 99% depending on query characteristics. Three decades of IR optimization research transfer directly into the Bayesian framework as mathematically valid pruning, not heuristics.
For Oatmeal, this means search that gets more accurate today and gets faster as your archive grows — a property that matters when you’re accumulating years of professional conversations.
Open Source
The work is fully open:
- Paper (Bayesian BM25): DOI 10.5281/zenodo.18414941 — CC BY 4.0
- Paper (Log-odds Conjunction): DOI 10.5281/zenodo.18514855 — CC BY 4.0
- Reference implementation (Python): github.com/jaepil/bayesian-bm25 — 11 modules, zero dependencies
- Blog: segfaults.co — essays on database internals, search theory, and the intersection of math and computation
What’s Next
This lays the foundation for memory that scales. When you’ve accumulated hundreds of meetings over a year — 200+ people mentioned, 50+ projects discussed, 1000+ decisions recorded — the difference between “search your meetings” and “understand your meetings” comes down to how well the system combines what it knows.
Keywords find exact words. Semantics find related concepts. Entity awareness finds the right people and projects. Temporal context finds the right time period. When all four agree, confidence rises naturally, surfacing the meetings that actually matter.
Search that understands meetings. Not because we built something complicated, but because the math was already there — waiting to be applied.
Oatmeal is a memory-native meeting notes app for macOS with fully local speech-to-text, AI, and search. Your audio never leaves your device.