The Rise of Local Speech Recognition
In 2019, Google’s cloud speech API achieved 4.9% word error rate—a milestone that required massive datacenters and years of research. By January 2026, a 600-million-parameter model running on a MacBook Air hits 6.05% WER while processing audio 50x faster than real-time. No internet connection. No API calls. No subscription.
This is the story of how speech recognition escaped the cloud.
Part I: The Deep Learning Earthquake (2009-2015)
The Old World: Statistical Models and Phoneme Soup
Before deep learning, speech recognition was a domain of carefully engineered pipelines. Systems like CMU Sphinx (1990s) and HTK (Hidden Markov Model Toolkit) relied on statistical methods: acoustic models, language models, pronunciation dictionaries. Progress was incremental. Building a speech recognizer required PhD-level expertise and months of careful tuning.
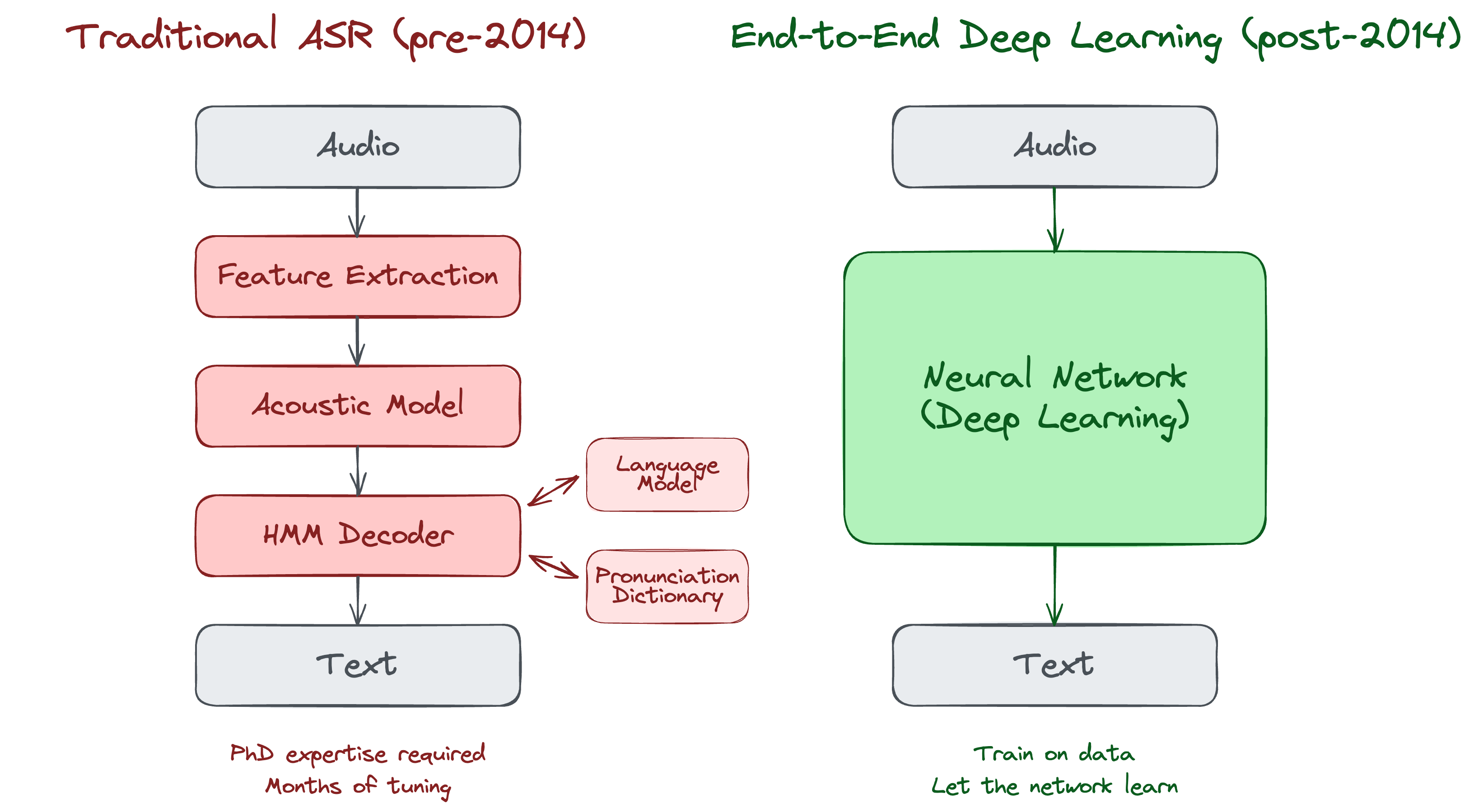
In 2009, researchers at Johns Hopkins began building Kaldi—named after the Ethiopian goatherd who discovered coffee.
Kaldi (released May 14, 2011) became the foundation of modern ASR research. It was:
- Open source (Apache 2.0 license)
- Highly flexible and modular
- Built with state-of-the-art HMM-based methods
Its foundational paper has been cited over 6,000 times.
The 2012 Breakthrough: Neural Networks Return
Geoffrey Hinton had been working on neural networks since the 1980s, long before it was fashionable. In 2009, Microsoft researcher Li Deng invited Hinton to Redmond. The collaboration produced stunning results.
Peter Lee, then cohead of Microsoft Research, later recalled:
“We were shocked by the results. We were achieving more than 30% improvements in accuracy with the very first prototypes.”
The technique: deep neural networks for acoustic modeling. Instead of hand-crafted features and statistical models, they trained multi-layer neural networks directly on speech data.
On September 30, 2012, Hinton’s student Alex Krizhevsky won the ImageNet competition with AlexNet, halving the previous best error rate. This wasn’t speech recognition, but it proved deep learning worked at scale. Google immediately hired Hinton and his students.
By August 2012, Google had integrated deep learning into its commercial speech recognition. Microsoft had done so in 2011. The neural network winter was over.
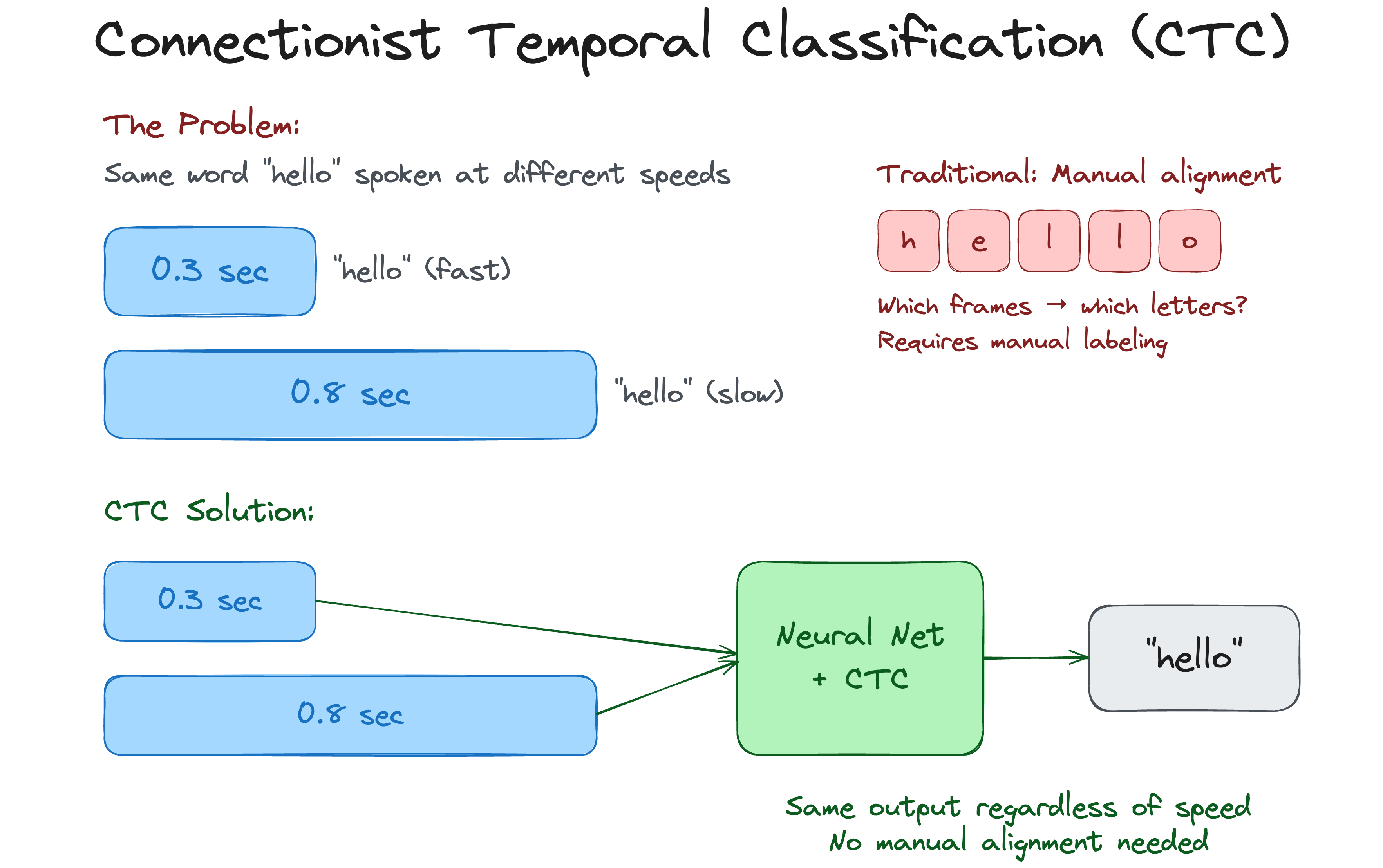
CTC: The Missing Piece (Originally 2006)
One critical technique made end-to-end speech recognition possible: Connectionist Temporal Classification (CTC), developed by Alex Graves and colleagues at IDSIA in Switzerland.
The problem: speech segments don’t align neatly with text labels. The word “hello” might take 0.3 seconds or 0.8 seconds to say. Traditional systems required painstaking pre-alignment of training data.
CTC solved this elegantly. It allowed neural networks to be trained on unsegmented sequences, learning the alignment automatically. The 2006 paper was ahead of its time—it would take nearly a decade for hardware to catch up.
Baidu’s Deep Speech: Challenging the Giants (2014-2015)
In December 2014, Baidu Research—led by Andrew Ng—announced Deep Speech. This wasn’t an incremental improvement. It was a complete rethinking of how speech recognition should work.
Deep Speech used:
- End-to-end learning (no phoneme dictionaries)
- Massive training data (100,000+ hours, including synthesized noisy data)
- CTC loss function for alignment-free training
The results: 16.5% Word Error Rate on the Switchboard benchmark, beating Google, Apple, and Microsoft’s APIs. More importantly, it handled noisy environments that destroyed traditional systems.
Deep Speech 2 (November 2015) went further:
- Worked on both English and Mandarin (vastly different languages)
- Achieved 97% accuracy rate
- Recognized by MIT Technology Review as a 2016 Top 10 Breakthrough Technology
Andrew Ng commented:
“For short phrases, out of context, we seem to be surpassing human levels of recognition.”
Part II: Transformers Change Everything (2017-2020)
“Attention Is All You Need” (2017)
In June 2017, a team at Google published a paper that would reshape all of AI: “Attention Is All You Need”.
The paper introduced the Transformer architecture. Previous sequence models (RNNs, LSTMs) processed data sequentially—one word or frame at a time. Transformers used “self-attention” to process entire sequences in parallel, making them far faster to train on modern GPUs.
The paper’s authors—Ashish Vaswani, Noam Shazeer, Niki Parmar, and others—initially focused on machine translation. But the Transformer would prove universal. Within years, it dominated:
- Language models (GPT, BERT)
- Image generation (Vision Transformer)
- Speech recognition
As of 2025, the paper has been cited over 173,000 times—among the top ten most-cited papers of the 21st century. The title references “All You Need Is Love” by the Beatles. The name “Transformer”? Co-author Jakob Uszkoreit simply liked the sound of it.
Self-Supervised Learning: wav2vec 2.0 (2020)
Another breakthrough came from Facebook AI (now Meta) in 2020: wav2vec 2.0.
The insight: humans learn language from raw audio before they learn to read. Could machines do the same?
wav2vec 2.0 used self-supervised learning. The model was trained on 53,000 hours of unlabeled audio—no transcriptions needed. It learned to predict masked portions of audio, similar to how BERT predicts masked words in text.
The results were remarkable:
- With just 10 minutes of labeled training data, it matched previous systems trained on hundreds of hours
- With one hour of labeled data, it outperformed the previous state of the art on LibriSpeech
The implication: transcribed speech data is expensive. Raw audio is everywhere. wav2vec 2.0 shifted the bottleneck from “how much labeled data do you have” to “how much compute can you throw at unlabeled audio.” That’s a fundamentally different scaling curve.
Part III: The Whisper Revolution (2022-Present)
Whisper: Open Source Changes the Game (September 2022)
On September 21, 2022, OpenAI released Whisper under the MIT license.
Whisper wasn’t the most accurate speech recognizer ever built. It wasn’t the fastest. What made it revolutionary was the combination:
- Trained on 680,000 hours of multilingual data from the web
- Multitask: transcription, translation, language detection, timestamp generation
- Robust: performed well across accents, background noise, and domains
- Open source: code and weights freely available to anyone
The training data was key. Previous models were trained on “clean” datasets—professional recordings, read speech, controlled conditions. Whisper was trained on the messy real world: YouTube videos, podcasts, lectures. It worked where other models failed.
From OpenAI’s announcement:
“While Whisper models cannot be used for real-time transcription out of the box, their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition.”
They were right.
The Paper (December 2022)
The full technical paper, “Robust Speech Recognition via Large-Scale Weak Supervision,” was published on arXiv in December 2022 and later presented at ICML 2023.
Key technical details:
- Architecture: Encoder-decoder Transformer
- Training data: 680,000 hours (117,000 hours in 96+ languages)
- Models: Multiple sizes from 39M to 1.55B parameters
- Zero-shot: No fine-tuning on benchmark datasets—pure generalization
The paper’s authors included Alec Radford and Ilya Sutskever, both key figures in OpenAI’s founding.
The Ecosystem Explodes
Within months:
Faster-Whisper (SYSTRAN): A reimplementation using CTranslate2, achieving 4x speed improvement with identical accuracy. Used techniques like int8 quantization and batched inference.
Distil-Whisper (Hugging Face, 2023): Knowledge distillation reduced the model to just 2 decoder layers. Result: 6x faster, 49% smaller, within 1% of original accuracy.
WhisperX: Added voice activity detection, forced alignment for word-level timestamps, and speaker diarization.
Commercial Products:
- MacWhisper ($40 lifetime): Polished Mac app for transcription
- SuperWhisper: Local dictation for Mac/iOS
- Wispr Flow (~$10/month): Cloud-based dictation with context awareness
- Gladia: Enterprise API built on enhanced Whisper
By December 2025, Whisper had 4.1 million monthly downloads on Hugging Face—the most-accessed open-source speech recognition model in history.
Whisper Timeline
| Date | Release | Key Change |
|---|---|---|
| Sep 21, 2022 | Whisper (original) | Initial release, MIT license |
| Dec 8, 2022 | Large-v2 | Refined training, same architecture |
| Mar 1, 2023 | Whisper API | OpenAI hosted service at $0.006/minute |
| Nov 6, 2023 | Large-v3 | 5M hour training dataset |
| Oct 1, 2024 | Large-v3-turbo | 4 decoder layers (from 32), 8x faster |
Part IV: Apple Silicon and the Local AI Revolution (2023-Present)
Apple MLX: Machine Learning Comes Home (December 2023)
In December 2023, Apple quietly released MLX—a machine learning framework optimized for Apple Silicon.
The timing was deliberate. Apple’s M-series chips (M1, M2, M3, M4) feature unified memory architecture: CPU and GPU share the same RAM. This eliminates the bottleneck of copying data between CPU and GPU memory—a massive advantage for machine learning workloads.
MLX was designed by Apple machine learning researchers, inspired by PyTorch and JAX. It featured:
- Lazy computation: Operations only execute when results are needed
- Dynamic graphs: No recompilation when input shapes change
- Unified memory: Arrays live in shared memory accessible by CPU and GPU
The release announcement:
“Just in time for the holidays, we are releasing some new software today from Apple machine learning research. MLX is an efficient machine learning framework specifically designed for Apple silicon (i.e. your laptop!)”
Within months, the community ported:
- mlx-whisper: Whisper running natively on Apple Silicon
- parakeet-mlx: NVIDIA’s Parakeet models on Mac
- mlx-audio: Full TTS/STT/STS library
- Large language models (Llama, Mistral, Qwen)
For the first time, you could run state-of-the-art AI models on a MacBook Air without internet access.
Apple SpeechAnalyzer: Native On-Device Transcription (WWDC 2025)
At WWDC 2025, Apple introduced SpeechAnalyzer—a replacement for SFSpeechRecognizer that runs entirely on-device.
Key improvements:
- Fully on-device: Complete privacy, no network required
- Long-form optimized: Designed for meetings, lectures, and extended audio
- 2.2x faster than Whisper Large-v3-turbo in benchmarks
- Distant audio support: Works with far-field microphones, not just close-up
- Automatic language detection: No manual configuration needed
The architecture includes SpeechTranscriber (speech-to-text) and SpeechDetector (voice activity detection), with models stored in a system-wide asset catalog—no impact on app bundle size.
Available on iPhone, iPad, Mac, and Vision Pro. For developers building on Apple platforms, this is the new baseline.
NVIDIA Parakeet: A New Benchmark (2024-2025)
In January 2024, NVIDIA released Parakeet, a family of ASR models through their NeMo framework, optimized for speed without sacrificing accuracy.
| Model | Parameters | WER | RTFx (Speed) |
|---|---|---|---|
| Parakeet-TDT 0.6B-v2 | 600M | 6.05% | 3,380 |
| Whisper Large-v3 | 1.55B | 7.4% | ~68 |
That’s not a typo. Parakeet is ~50x faster than Whisper Large while achieving better accuracy.
The secret: NVIDIA’s FastConformer architecture—an optimized Conformer with 8x depthwise-separable convolutional downsampling—combined with the TDT (Token-and-Duration Transducer) decoder. TDT decouples token and duration predictions, enabling the model to skip blank predictions and achieve massive speed improvements.
Timeline:
- Jan 3, 2024: Parakeet family announced (RNNT and CTC variants), trained on 64,000 hours
- May 1, 2025: Parakeet-TDT 0.6B-v2 released, trained on 120,000 hours (Granary dataset)
- Jul 2025: NVIDIA Canary Qwen 2.5B takes #1 on leaderboard (5.63% WER)
- Aug 2025: Parakeet 0.6B-v3 with 25 European languages, trained on ~1 million hours
Parakeet-TDT briefly held #1 on the Hugging Face Open ASR Leaderboard. As of January 2026, NVIDIA Canary Qwen 2.5B leads with 5.63% WER—a hybrid model combining FastConformer encoder with Qwen3-1.7B as the LLM decoder. Parakeet remains the speed champion for real-time applications.
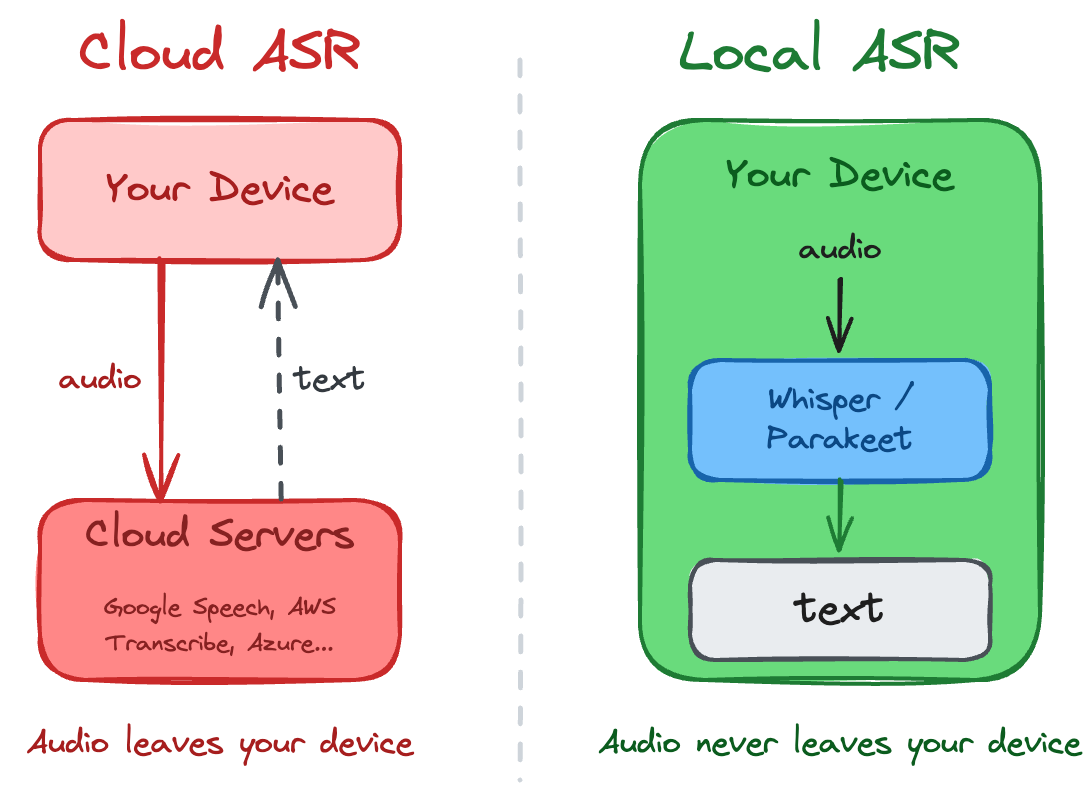
The Local-First Movement
By 2026, a clear trend emerged: local-first AI.
Drivers:
- Privacy: GDPR and similar regulations pushed enterprises to self-hosted solutions
- Cost: Cloud APIs charge per minute; local models have zero marginal cost
- Latency: No network round-trip means faster response
- Reliability: Works offline, on airplanes, with poor connectivity
CES 2026 was dominated by on-device AI announcements. Qualcomm’s Snapdragon X2 Plus features an 80 TOPS NPU. Intel’s Core Ultra Series 3 runs on their 18A process node. Every major chip maker is betting on edge inference—not as a fallback to cloud, but as the primary deployment target.
The implication for speech recognition is straightforward: when the model runs locally, audio never leaves your device. No transmission to intercept. No server to breach. No third-party retention policy to parse.
Beyond Transformers: New Architectures (2025)
Two developments in 2025 challenged the Transformer’s dominance in ASR:
Samba-ASR (January 2025): The first state-of-the-art ASR model using the Mamba architecture instead of Transformers. Mamba is a state-space model with linear complexity—it processes sequences without the quadratic scaling that limits Transformers on long audio. For lengthy recordings, this matters.
Meta Omnilingual ASR (November 2025): While Whisper supports 99 languages, Meta’s model handles 1,600+—with zero-shot capability extending to potentially 5,400 languages. This is speech recognition for the long tail: endangered languages, regional dialects, communities that billion-parameter models typically ignore. Released fully open source.
Both represent inflection points: Samba shows Transformers aren’t the only path to SOTA; Meta shows that “multilingual” doesn’t have to mean “the languages with the most training data.”
Part V: The State of the Art (2026)
What’s Possible Today
In January 2026, anyone with a modern laptop can:
- Transcribe speech with <6% word error rate
- Dictate with automatic punctuation and capitalization
- Process audio in real-time (faster than speaking speed)
- Do all of this completely offline, with no cloud dependency
The quality matches—and often exceeds—paid cloud services from just a few years ago.
The Key Models
| Model | Best For | Size | WER | Speed |
|---|---|---|---|---|
| Canary Qwen 2.5B | Highest accuracy | 2.5B | 5.63% | 418 RTFx |
| Parakeet TDT 0.6B-v3 | Fast English + 25 EU languages | 600M | 6.05% | 3,380 RTFx |
| Whisper Large-v3 | Multilingual (99 languages) | 1.55B | 7.4% | ~68 RTFx |
| Whisper Large-v3-turbo | Balance of speed/accuracy | 809M | ~7% | ~550 RTFx |
| Meta Omnilingual | 1,600+ languages | 7B | varies | — |
| Apple SpeechAnalyzer | Native Apple apps | system | — | 2.2x Whisper |
Conclusion
None of this was inevitable. Each breakthrough built on the last:
- CTC (2006) → enabled end-to-end training
- Deep learning (2012) → massive accuracy improvements
- Transformers (2017) → parallelization and scale
- Self-supervised learning (2020) → reduced data requirements
- Whisper (2022) → democratized access through open source
- Apple Silicon + MLX (2023) → efficient on-device inference
- Parakeet (2024) → speed without compromise
- Samba-ASR + Meta Omnilingual (2025) → new architectures, 1,600+ languages
- Apple SpeechAnalyzer (2025) → native platform integration
But none of it was obvious at the time. Geoffrey Hinton worked on neural networks for decades before they became fashionable. Alex Graves published CTC eight years before Deep Speech made it famous. The Mamba architecture that powers Samba-ASR was a curiosity until it matched Transformer accuracy.
Today, you can speak to your laptop and have your words transcribed instantly, privately, and accurately. Your voice never leaves your device. No subscription. No corporation listening.
The research papers are dense with mathematics. The code is complex. The result is simple: your words, your device, your control.
Timeline: Key Milestones
| Year | Milestone | Significance |
|---|---|---|
| 2006 | CTC published | Enabled end-to-end ASR training |
| 2011 | Kaldi released | Open-source ASR toolkit |
| 2012 | AlexNet wins ImageNet | Deep learning revolution begins |
| 2014 | Deep Speech | End-to-end learning proves viable |
| 2017 | Transformers paper | New architecture reshapes AI |
| 2020 | wav2vec 2.0 | Self-supervised speech learning |
| 2022 | Whisper released | Open-source revolution begins |
| 2023 | Apple MLX | Local ML on Apple Silicon |
| 2024 | NVIDIA Parakeet | 50x faster than Whisper |
| 2025 | Samba-ASR | First Mamba-based SOTA ASR |
| 2025 | Meta Omnilingual | 1,600+ languages |
| 2025 | Apple SpeechAnalyzer | Native on-device transcription |
| 2025 | Canary Qwen 2.5B | Hybrid ASR+LLM takes #1 |
References
Seminal Research Papers
-
Connectionist Temporal Classification (CTC) Graves, A., Fernández, S., Gomez, F., & Schmidhuber, J. (2006). ICML 2006. https://www.cs.toronto.edu/~graves/icml_2006.pdf
-
Deep Neural Networks for Speech Hinton, G., Deng, L., Yu, D., et al. (2012). IEEE Signal Processing Magazine. https://www.cs.toronto.edu/~hinton/absps/DNN-2012-proof.pdf
-
Deep Speech Hannun, A., et al. (2014). https://arxiv.org/abs/1412.5567
-
Attention Is All You Need Vaswani, A., et al. (2017). NeurIPS 2017. https://arxiv.org/abs/1706.03762
-
wav2vec 2.0 Baevski, A., et al. (2020). NeurIPS 2020. https://arxiv.org/abs/2006.11477
-
Whisper Radford, A., et al. (2022). ICML 2023. https://arxiv.org/abs/2212.04356
-
Fast Conformer (Parakeet architecture) Rekesh, D., et al. (2023). NVIDIA NeMo. https://arxiv.org/abs/2305.05084
-
Samba-ASR Shih, Y., et al. (2025). https://arxiv.org/abs/2501.02832
-
Meta Omnilingual ASR Meta AI (2025). https://ai.meta.com/research/publications/omnilingual-asr/
Models & Code
| Resource | URL |
|---|---|
| OpenAI Whisper | https://github.com/openai/whisper |
| NVIDIA Parakeet | https://huggingface.co/nvidia/parakeet-tdt-0.6b-v3 |
| NVIDIA Canary Qwen | https://huggingface.co/nvidia/canary-qwen-2.5b |
| Apple MLX | https://github.com/ml-explore/mlx |
| Apple SpeechAnalyzer | https://developer.apple.com/videos/play/wwdc2025/277/ |
| Faster-Whisper | https://github.com/SYSTRAN/faster-whisper |
| Distil-Whisper | https://github.com/huggingface/distil-whisper |
| Samba-ASR | https://arxiv.org/abs/2501.02832 |